Abstract
Adaptive gradient methods for stochastic optimization adjust the learning rate for each parameter locally. However, there is also a global learning rate which must be tuned in order to get the best performance. In this paper, we present a new algorithm that adapts the learning rate locally for each parameter separately, and also globally for all parameters together. Specifically, we modify Adam, a popular method for training deep learning models, with a coefficient that captures properties of the objective function. Empirically, we show that our method, which we call Eve, outperforms Adam and other popular methods in training deep neural networks, like convolutional neural networks for image classification, and recurrent neural networks for language tasks.
1 Introduction
Training deep neural networks is a challenging non-convex optimization problem. SGD (Stochastic Gradient Descent) is a simple way to move towards local optima by following the negative (sub)gradient. However, vanilla SGD is slow in achieving convergence for large-scale problems. One issue arises from the use of a global learning rate, which is difficult to set. To prevent the loss from “bouncing around” or diverging in directions with high curvature, the learning rate must be kept small. But this leads to slow progress in directions with low curvature. In many problems, the sparsity of gradients creates an additional challenge for SGD. Some parameters might be used very infrequently, but still be very informative. Therefore, these parameters should be given a large learning rate when observed.
The issues highlighted above motivate the need for adaptive learning rates that are local to each parameter in the optimization problem. While there has been much work in this area, here we focus on the family of methods based on the Adagrad algorithm1. These methods maintain a separate learning rate for each parameter; and these local learning rates are made adaptive using some variation of the sum of squared gradients. Roughly speaking, if the gradients for some parameter have been large, its learning rate is reduced; and if the gradients have been small, the learning rate is increased. Variations of Adagrad such as RMSprop2, Adadelta3, or Adam4 are, by far, the most popular alternatives to vanilla SGD for training deep neural networks.
In addition to parameter-specific local learning rates, the adaptive methods described above also have a global learning rate which determines the overall step size. In many cases, this global learning rate is left at its default value; however, to get the best performance, it needs to be tuned, and also adapted throughout the training process. A common strategy is to decay the learning rate over time, which adds an additional hyperparameter, the decay strength, that needs to be chosen carefully.
In this work, we address the problem of adapting the global learning rate with a simple method that incorporates “feedback” from the objective function. Our algorithm, Eve, introduces a scalar coefficient which is used to adapt the global learning rate to be , where is the initial learning rate. depends on the history of stochastic objective function evaluations, and captures two properties of its behavior: variation in consecutive iterations and sub-optimality. Intuitively, high variation should reduce the learning rate and high sub-optimality should increase the learning rate. We specifically apply this idea to Adam4, a popular method for training deep neural networks.
2 Related work
Our work builds on recent advancements in gradient based optimization methods with locally adaptive learning rates. Notable members in this family are Adagrad1, Adadelta3, RMSProp2, Adam/Adamax4. These methods adapt the learning rate using sum of squared gradients, an estimate of the uncentered second moment. Some of these methods also use momentum, or running averages instead of the raw gradient. Being first-order methods, they are simple to implement, and computationally efficient. In practice, they perform very well and are the methods of choice for training large neural networks.
As was discussed in the introduction, these methods have a global learning rate which is generally constant or annealed over time. Two popular decay algorithms are exponential decay which sets , and decay which sets . Here is the decay strength, is iteration number, and is the initial learning rate. For Adam, 4 suggest decay which sets . We compare our proposed method with Adam using these decay algorithms. There are other heuristic scheduling algorithms used in practice like reducing the learning rate by some factor after every some number of iterations, or reducing the learning rate when the loss on a held out validation set stalls. 5 proposes a schedule where the learning rate is varied cyclically between a range of values.
6 take up the more ambitious goal of completely eliminating the learning rate parameter, with a second-order method that computes the diagonal Hessian using the bbprop algorithm7. Note, however, that the method is only applicable under mean squared error loss. Finally, for convex optimization, 8 proposes a way to select step sizes for the subgradient method when the optimum is known. It can be shown that with steps of size (where is a subgradient), the subgradient method converges to the optimal value under some conditions. Our method also makes use of the optimal value for adapting the global learning rate.
3 Method
3.1 Preliminaries: Adam
Since our method builds on top of the Adam algorithm, we begin with a brief description of the method. First, we establish the notation: let be a stochastic objective function with parameters , and let be the value of the parameters after time . Let and . Adam maintains a running average of the gradient given by with . A correction term is applied to remove the bias caused by initializing with 0. is an unbiased estimate of the gradient’s first moment assuming stationarity (). A similar term is computed using the squared gradients: is an unbiased estimate of the gradient’s uncentered second moment (). Then, Adam updates parameters using the update equation
3.2 Proposed method: Eve
Our method is motivated by simple intuitive arguments. Let denote the stochastic objective function that needs to be minimized. Let be it’s value at iteration , and let be its global minimum. First, consider the quantity . This captures the variability in the objective function i.e., how much the function is changing from one step to the other. If this quantity is large, any particular stochastic evaluation of should be given less “weight”, and the step taken based on it should be small. So we would like the learning rate to depend inversely on . Next, consider the quantity , where is the expected global minimum of . This is the sub-optimality i.e., it denotes how far we are from the minimum at time . Intuitively, far from the minimum, we should take big steps to make quick progress, and if we are close to the minimum, we should take small steps. Hence we would like the learning rate to depend directly on . Putting these two together, our method scales the learning rate by : However, this simple method is not stable because once the loss increases, the increase of numerator in Equation 5 directly increases the learning rate. This can result in the learning rate blowing up due to taking an even bigger step, causing the numerator to further increase, and so forth. To prevent this, we make modifications to stabilize the update rule by first replacing in the numerator of Equation 5 with . This will reduce the chance of the vicious cycle mentioned above by keeping the numerator at the same value if the loss increases. In addition, we clip the term with a range parameterized by a constant to avoid extreme values. Finally, for smoothness, we take a running average of the clipped The learning rate is then given by . Thus, the learning rate will be in the range . Combining this with the Adam update rule gives our complete algorithm, which we call Eve, and is shown in Figure 1. Below, the equations for computing are summarized. We set , and for , we have 
3.3 Discussion of limitations
One condition of our method, which can also be construed as a limitation, is that it requires knowledge of the global minimum of the objective function . However, the method still remains applicable to a large class of problems. Particularly in deep learning, regularization is now commonly performed indirectly with dropout9 or batch normalization10 rather than weight decay. Therefore, under mean squared error or cross-entropy loss functions, the global minimum is simply 0. This will be the case for all our experiments, and we show that Eve can improve over other methods in optimizing complex, practical models.
4 Experiments
Now we conduct experiments to compare Eve with other popular optimizers used in deep learning. We use the same hyperparameter settings (as described in Figure 1) for all experiments. We also conduct an experiment to study the behavior of Eve with respect to the new hyperparameters and . For each experiment, we use the same random number seed when comparing different methods. This ensures same weight initializations (we use the scheme proposed by 11 for all experiments), and mini-batch splits. In all experiments, we use cross-entropy as the loss function, and since the models don’t have explicit regularization, is set to 0 for training Eve.
4.1 Training CNNs
First we compare Eve with other optimizers for training a CNN (Convolutional Neural Network). The optimizers we compare against are Adam, Adamax, RMSprop, Adagrad, Adadelta, and SGD with Nesterov momentum12 (momentum ). The learning rate was searched over , , , , , , , , , , , and the value which led to the lowest final loss was selected for reporting results. For Adagrad, Adamax, and Adadelta, we additionally searched over the prescribed default learning rates (, , and respectively).
The model is a deep residual network13 with 16 convolutional layers. The network is regularized with batch normalization and dropout, and contains about 680,000 parameters, making it representative of a practical model.
Figure 2(a) shows the results of training this model on the CIFAR 100 dataset14 for 100 epochs with a batch size of 128. We see that Eve outperforms all other algorithms by a large margin. It quickly surpasses other methods, and achieves a much lower final loss at the end of training.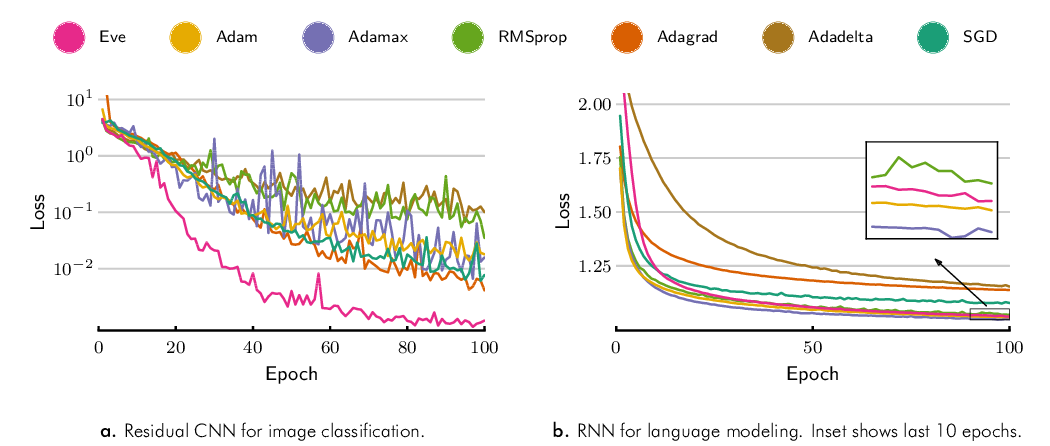
4.2 Training RNNs
We also compare our method with other optimizers for training RNNs (Recurrent Neural Networks). We use the same algorithms as in the previous experiment, and the learning rate search was conducted over the same set of values.
We construct a RNN for character-level language modeling task on PTB (Penn Treebank)15. Specifically, the model consists of a 2-layer character-level GRU (Gated Recurrent Unit)16 with hidden layers of size 256, with 0.5 dropout between layers. The sequence length is fixed to 100 characters, and the vocabulary is kept at the original size.
The results for training this model are shown in Figure 2(b). Different optimizers performed similarly on this task, with Eve achieving slightly higher loss than Adam and Adamax.
4.3 Comparison with decay strategies
We also empirically compare Eve with three common decay policies: exponential (), (), and (). We consider the same CIFAR 100 classification task described in Section 4.1, and use the same CNN model. We applied the three decay policies to Adam, and tuned both the initial learning rate and decay strength. Learning rate was again searched over the same set as in the previous experiments.
For , we searched over a different set of values for each of the decay policies, such that final learning rate after 100 epochs would be where is in , , , , , , , .
Figure 3(a) compares Eve with the best exponential decay, the best decay, and the best decay applied to Adam. We see that using decay closes some of the gap between the two algorithms, but Eve still shows faster convergence. Moreover, using such a decay policy requires careful tuning of the decay strength. As seen in Figure 3(b), for different decay strengths, the performance of Adam can vary a lot. Eve can achieve similar or better performance without tuning an additional hyperparameter.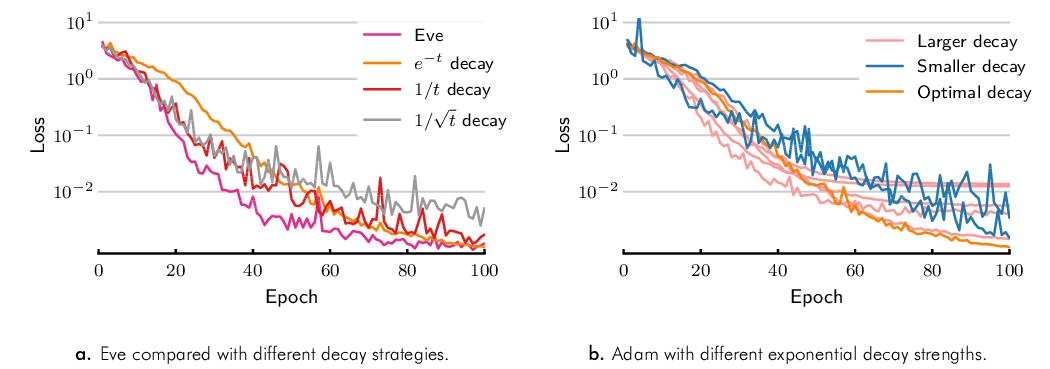
4.4 Effect of hyperparameters
In this experiment, we study the behavior of Eve with respect to the two hyperparameters introduced over Adam: and . We use the previously presented ResNet model on CIFAR 100, and a RNN model trained for question answering, on question 14 (picked randomly) of the bAbI-10k dataset17. The question answering model composes two separate GRUs (with hidden layers of size 256 each) for question sentences, and story passages.
We trained the models using Eve with in , , , , , , , , , , , , , , and in , , , , , , . For each pair, we picked the best learning rate from the same set of values used in previous experiments. We also used Adam with the best learning rate chosen from the same set as Eve.
Figure 4 shows the loss curves for each hyperparameter pair, and that of Adam. The bold line in the figure is for , which are the default values. For these particular cases, we see that for almost all settings of the hyperparameters, Eve outperforms Adam, and the default values lead to performance close to the best. In general, for different models and/or tasks, not all hyperparameter settings lead to improved performance over Adam, and we did not observe any consistent trend in the performance across hyperparameters. However, the default values suggested in this paper consistently lead to good performance on a variety of tasks. We also note that the default hyperparameter values were not selected based on this experiment, but through an informal initial search using a smaller model.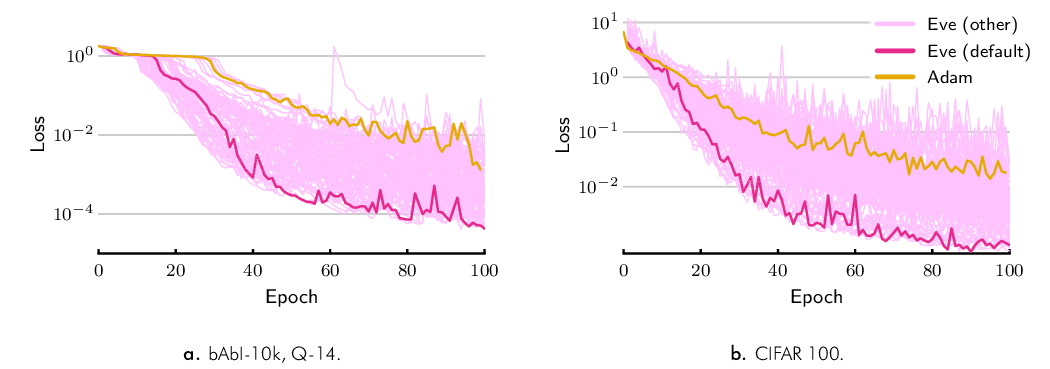
5 Conclusion and Future Work
We proposed a new algorithm, Eve, for stochastic gradient-based optimization. Our work builds on adaptive methods which maintain a separate learning rate for each parameter, and adaptively tunes the global learning rate using feedback from the objective function. Our algorithm is simple to implement, and is efficient, both computationally, and in terms of memory.
Through experiments with CNNs and RNNs, we showed that Eve outperforms other state of the art optimizers in optimizing large neural network models. We also compared Eve with learning rate decay methods and showed that Eve can achieve similar or better performance with far less tuning. Finally, we studied the hyperparameters of Eve and saw that a range of choices leads to performance improvement over Adam.
One limitation of our method is that it requires knowledge of the global minimum of the objective function. One possible approach to address this issue is to use an estimate of the minimum, and update this estimate as training progresses. This approach has been used when using Polyak step sizes with the subgradient method.
References
- Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research. 2011;12(Jul):2121–59.
- Tieleman T, Hinton G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning. 2012;4(2):26–31.
- Zeiler MD. ADADELTA: An adaptive learning rate method. arXiv preprint arXiv:12125701. 2012;
- Kingma D, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:14126980. 2014;
- Smith LN. Cyclical learning rates for training neural networks. In: Applications of computer vision (WACV), 2017 IEEE winter conference on. IEEE; 2017. p. 464–72.
- Schaul T, Zhang S, LeCun Y. No more pesky learning rates. In: International conference on machine learning. 2013. p. 343–51.
- LeCun Y, Bottou L, Orr GB, Müller K-R. Efficient backprop. In: Neural networks: Tricks of the trade. Springer; 1998. p. 9–50.
- Polyak BT. Introduction to optimization. Translations series in mathematics and engineering. Optimization Software. 1987;
- Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research. 2014;15(1):1929–58.
- Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:150203167. 2015;
- Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the thirteenth international conference on artificial intelligence and statistics. 2010. p. 249–56.
- Nesterov Y. A method for unconstrained convex minimization problem with the rate of convergence o (1/k^ 2). In: Doklady AN USSR. 1983. p. 543–7.
- He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 770–8.
- Krizhevsky A, Hinton G. Learning multiple layers of features from tiny images. 2009;
- Marcus MP, Marcinkiewicz MA, Santorini B. Building a large annotated corpus of english: The penn treebank. Computational linguistics. 1993;19(2):313–30.
- Chung J, Gulcehre C, Cho K, Bengio Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:14123555. 2014;
- Weston J, Bordes A, Chopra S, Rush AM, Merriënboer B van, Joulin A, et al. Towards ai-complete question answering: A set of prerequisite toy tasks. arXiv preprint arXiv:150205698. 2015;